Stelle VidToMe vor - es könnte die Open-Source-Gen-1 sein, auf die du gewartet hast! Mit Optionen für Textprompt-Video-Bearbeitungen, benutzerdefinierten Modellen und ControlNet-Anleitung bietet VidToMe eine außergewöhnliche zeitliche Konsistenz. Schon ein Beispiel für Pixelkunst und du wirst begeistert sein!
Diffusionsmodelle haben die hochwertige Bildgenerierung bahnbrechend vorangetrieben, doch ihre Anwendungen zur Videogenerierung sind aufgrund von zeitlichen Bewegungskomplexitäten ins Stocken geraten. Hier kommt die Videoschnitttechnik ohne Vorgabe von Bearbeitungsschritten ins Spiel, bei der vortrainierte Bilddiffusionsmodelle zur Neugestaltung von Originalvideos eingesetzt werden. Es bleiben jedoch Probleme wie die Aufrechterhaltung der zeitlichen Konsistenz und die effiziente Speichernutzung.
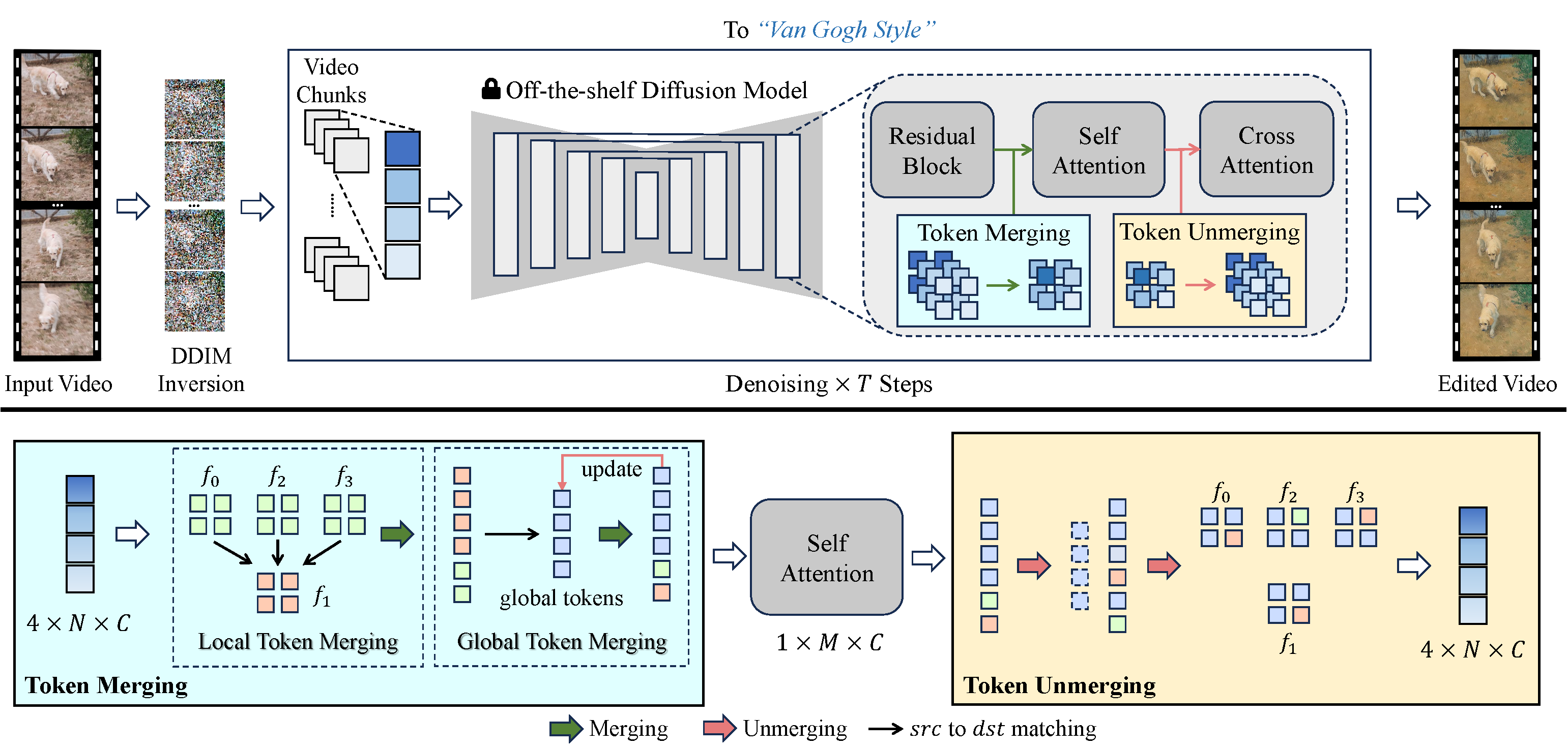
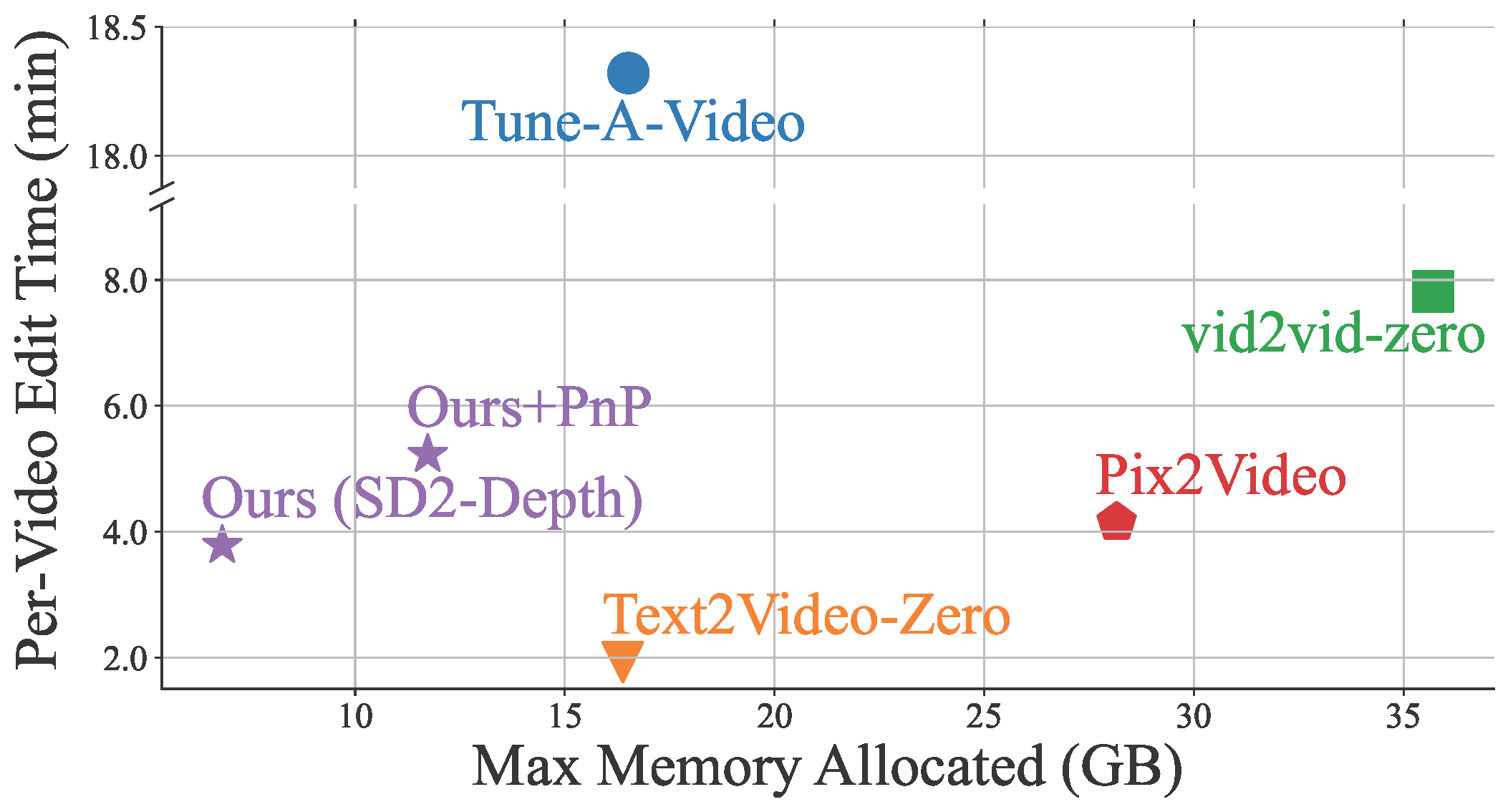
Wir haben uns einen frischen Ansatz überlegt, um diese Probleme zu lösen. Wir verbessern die zeitliche Konsistenz in generierten Videos, indem wir selbst-achtende Token über die Frames hinweg verweben. Durch Ausrichtung und Komprimierung zeitlich redundanter Token steigern wir die zeitliche Kohärenz und reduzieren den Speicherbedarf. Unser einzigartiger Zusammenführungsprozess ordnet die Token basierend auf der zeitlichen Beziehung zwischen den Videoframes an und gewährleistet somit eine natürliche Konsistenz des Videoinhalts.
VidToMe erledigt die aufwändige Videobearbeitung für dich. Wir teilen das Video in Abschnitte auf und wenden eine intra-abschnittliche lokale Token-Zusammenführung und eine inter-abschnittliche globale Token-Zusammenführung an. Dieser Ansatz garantiert eine kurz- und langfristige Kontinuität und Konsistenz des Videoinhalts. Unsere Videobearbeitungstechnik übertrifft bestehende Branchenstandards bei der Aufrechterhaltung der zeitlichen Konsistenz und schließt die Lücke zwischen Bild- und Videobearbeitung.
Build web-apps using plain english
VidToMe: Video Token Merging for Zero-Shot Video Editing