Presentamos VidToMe - ¡puede ser el Gen-1 de código abierto que has estado esperando! Repleto de opciones para ediciones de video con texto, modelos personalizados y guía de ControlNet, VidToMe ofrece una consistencia temporal excepcional. ¡Con tan solo un ejemplo de arte de píxel te engancharás!
Los modelos de difusión han sido pioneros en la generación de imágenes de alta calidad, pero sus aplicaciones para la generación de videos se han encontrado con obstáculos debido a las complejidades del movimiento temporal. Ahí es donde entra la edición de video sin necesidad de entrenamiento, aplicando modelos de difusión de imágenes preentrenados para reformatear videos originales. Sin embargo, siguen existiendo problemas como mantener la consistencia temporal y el uso eficiente de la memoria.
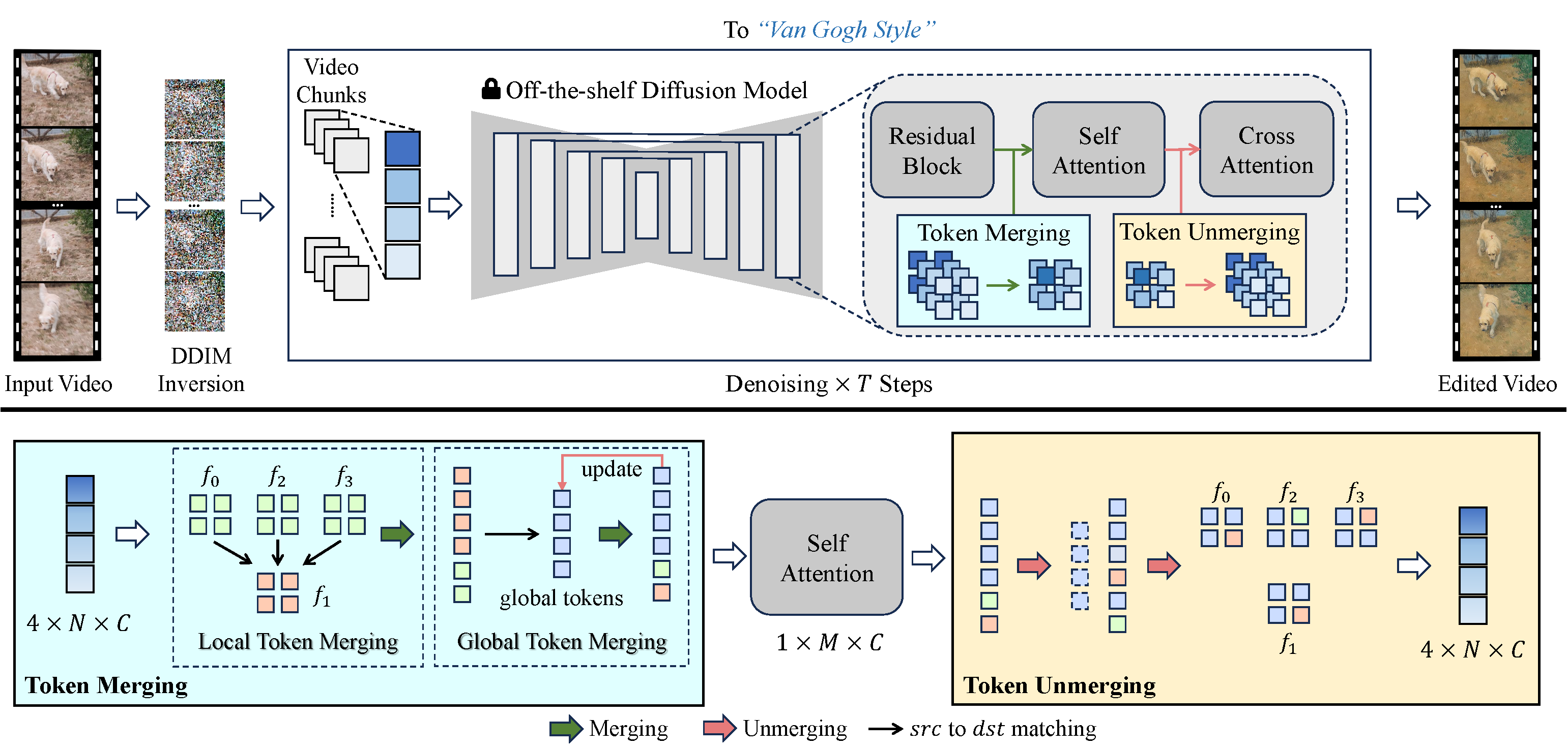
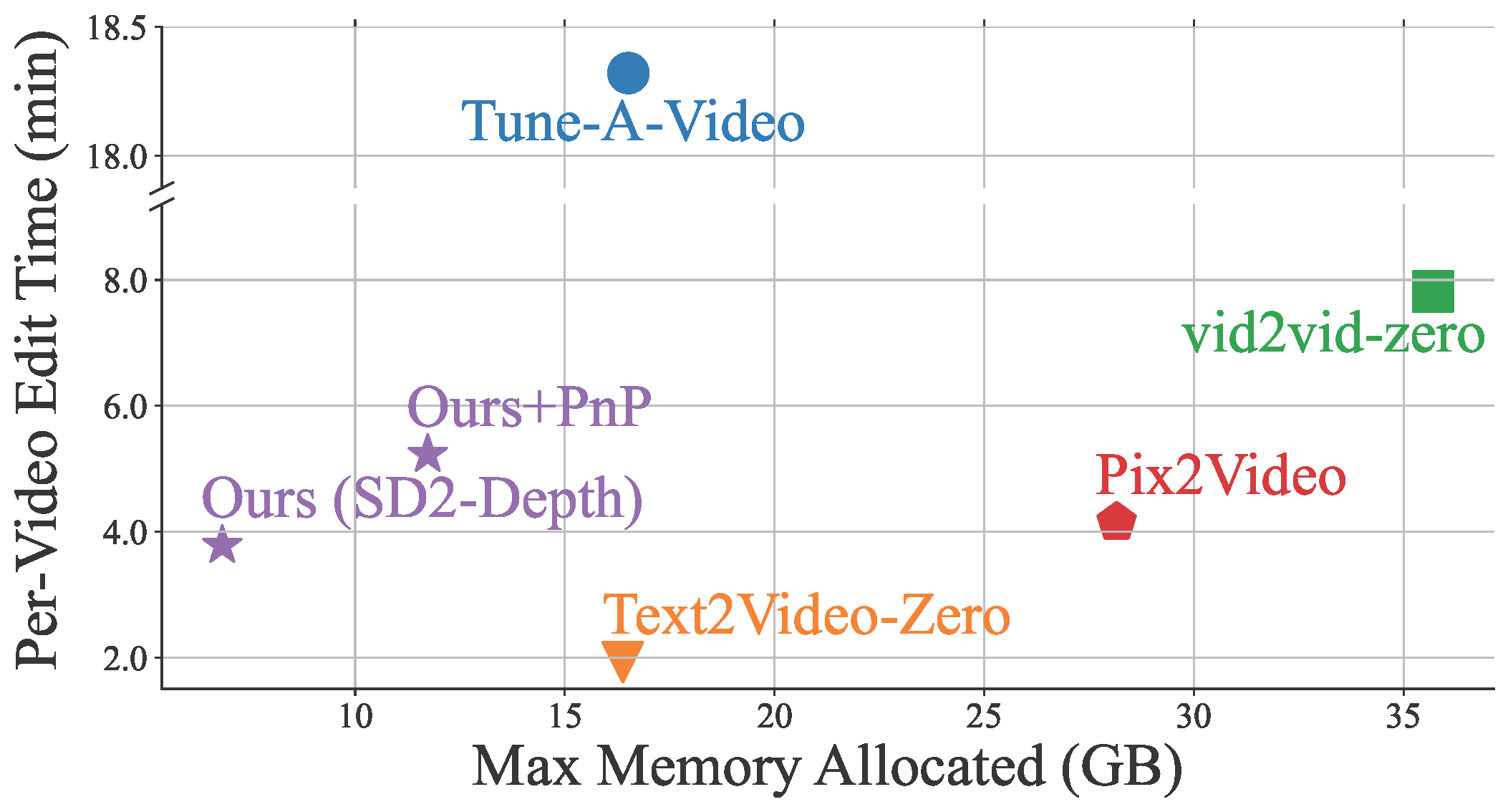
Hemos adoptado un enfoque fresco para resolver estos problemas. Mejoramos la consistencia temporal en los videos generados entrelazando tokens de autoatención en los fotogramas. Al alinear y comprimir tokens temporalmente redundantes, aumentamos la coherencia temporal y reducimos el uso de memoria. Nuestro proceso de fusión único alinea los tokens según la relación temporal entre los fotogramas del video, asegurando un contenido de video naturalmente consistente.
VidToMe se encarga de la tarea pesada del procesamiento de video. Dividimos el video en fragmentos y aplicamos la fusión de tokens locales intra-fragmento y la fusión global de tokens inter-fragmento. Este enfoque garantiza la continuidad y consistencia a corto y largo plazo del contenido de video. Al superar los estándares actuales de la industria en cuanto a la consistencia temporal, nuestra técnica de edición de video está cerrando la brecha entre la edición de imágenes y videos.
Build web-apps using plain english
VidToMe: Video Token Merging for Zero-Shot Video Editing