Présentation de VidToMe - c’est peut-être la Gen-1 open-source que vous attendiez ! Doté d’options pour des modifications de vidéo avec des prompts de texte, des modèles personnalisés et des directives de ControlNet, VidToMe offre une exceptionnelle cohérence temporelle. Il vous suffit d’un simple exemple d’art pixelisé et vous serez accro !
Les modèles de diffusion ont ouvert la voie à la génération d’images de haute qualité, mais leurs applications en génération de vidéos ont rencontré des difficultés en raison de la complexité du mouvement temporel. C’est là que l’édition de vidéos sans formation intervient, en appliquant des modèles de diffusion d’images pré-entraînés pour reformater les vidéos originales. Cependant, des problèmes tels que le maintien de la cohérence temporelle et l’utilisation efficace de la mémoire persistent.
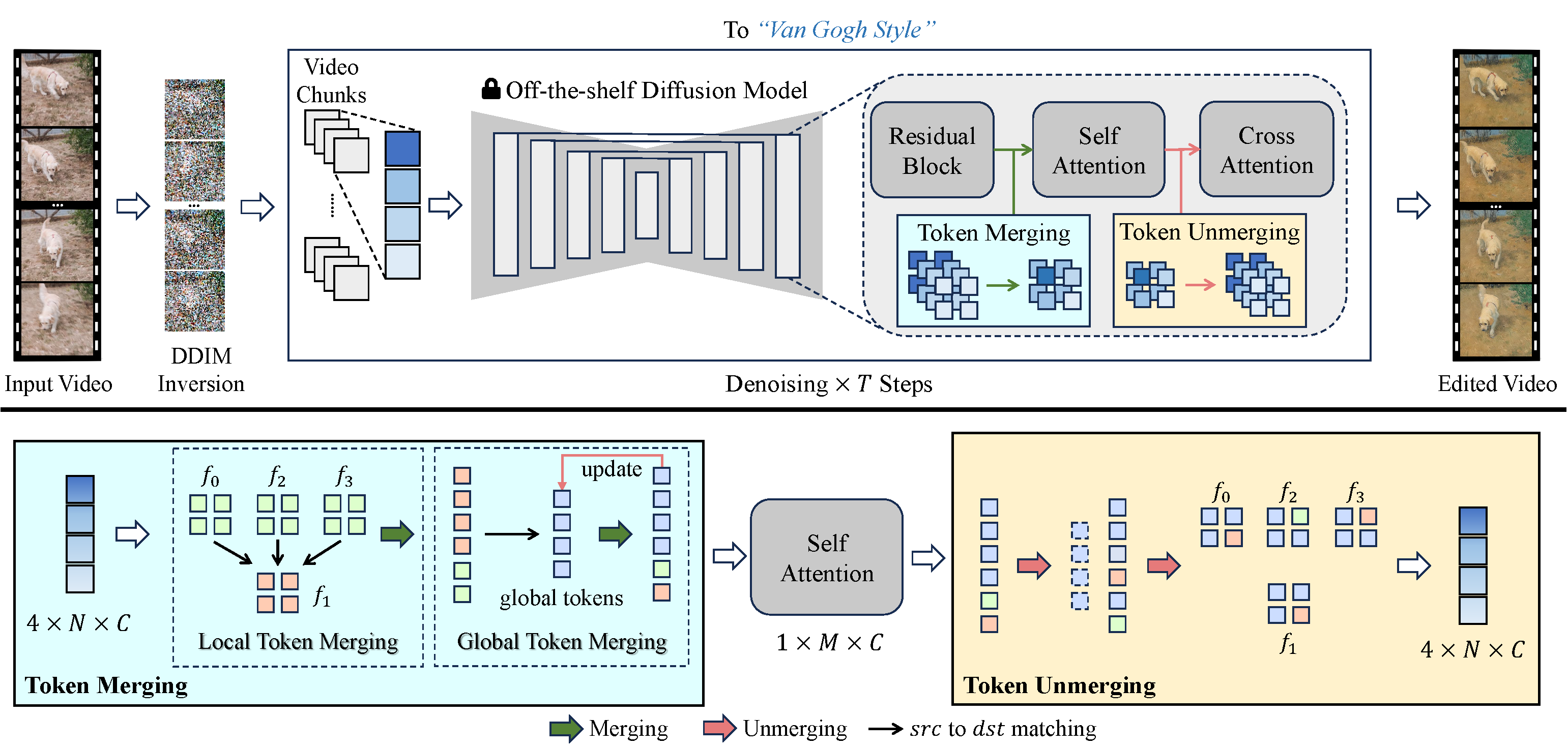
Nous avons adopté une approche nouvelle pour résoudre ces problèmes. Nous améliorons la cohérence temporelle dans les vidéos générées en entrelaçant des jetons d’auto-attention à travers les images. En alignant et en comprimant les jetons temporellement redondants, nous renforçons la cohérence temporelle et réduisons l’utilisation de la mémoire. Notre processus de fusion unique aligne les jetons en fonction de la relation temporelle entre les images vidéo, garantissant ainsi un contenu vidéo naturellement cohérent.
VidToMe prend en charge les traitements vidéo les plus lourds. Nous divisons la vidéo en morceaux et appliquons une fusion locale de jetons intra-morceaux et une fusion globale de jetons inter-morceaux. Cette approche garantit une continuité et une cohérence à court et long terme du contenu vidéo. En comblant le fossé entre l’édition d’images et de vidéos, notre technique d’édition vidéo dépasse les normes actuelles de l’industrie en matière de maintien de la cohérence temporelle.
Build web-apps using plain english
VidToMe: Video Token Merging for Zero-Shot Video Editing