Presentiamo EMO, un innovativo framework di Alibaba Group, progettato per dare vita a ritratti statici grazie alla potenza dell’audio. Basta fornire un’immagine di riferimento e una clip audio, come una voce che parla o canta, e EMO fa la sua magia per creare video di avatar vocali. Questi video non solo esprimono movimenti facciali, ma presentano anche varie posizioni della testa, capaci di adattarsi alla durata dell’audio fornito.
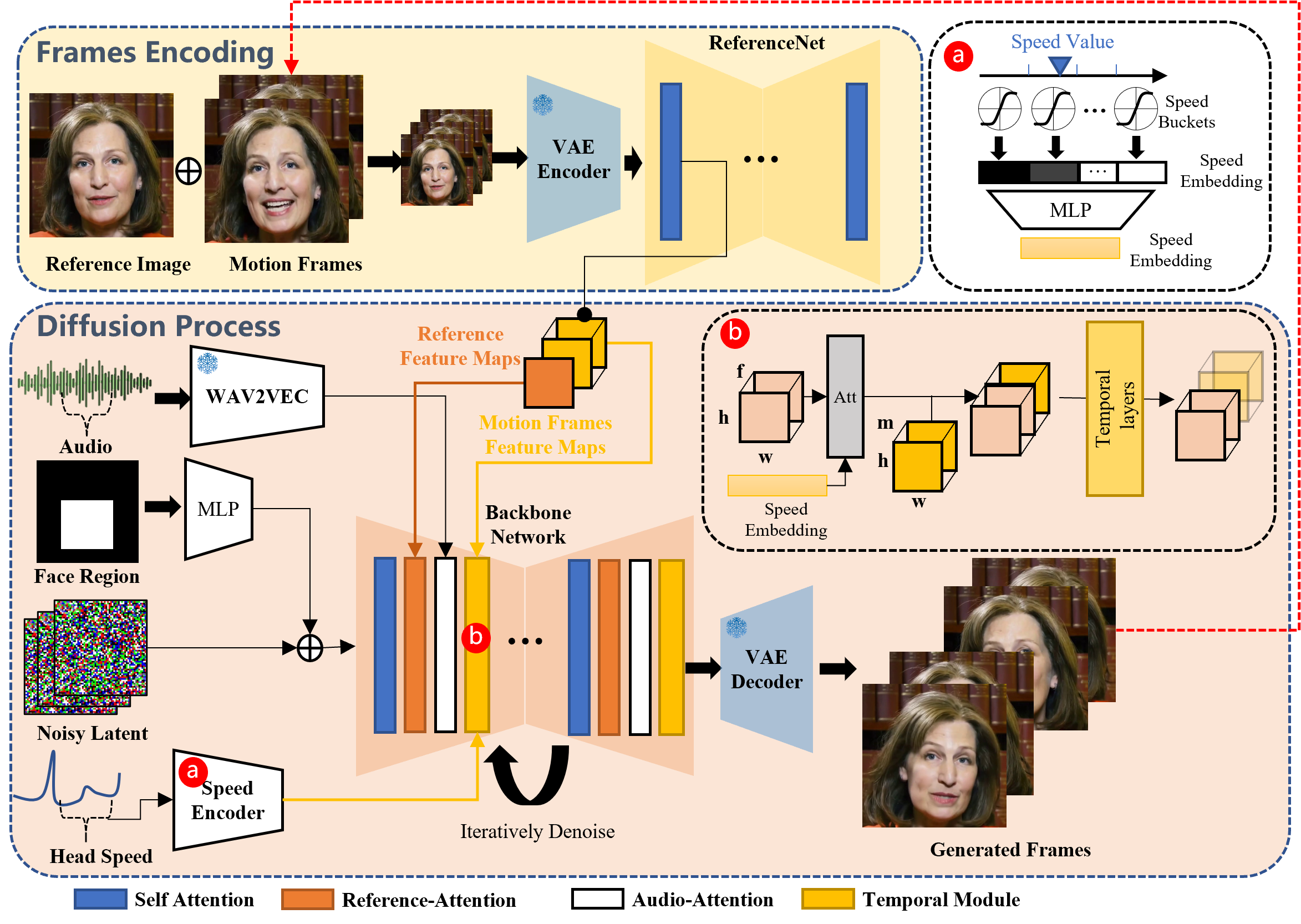
Come funziona EMO: EMO opera in due fasi principali:
- Codifica dei Frame: Utilizza ReferenceNet per analizzare l’immagine di riferimento e i frame di movimento, catturando le caratteristiche essenziali.
- Processo di Diffusione: Incorpora un coder audio pre-addestrato per gli embedding audio, mescolandolo con una maschera della regione facciale e il rumore multi-frame. La rete Backbone, dotata di meccanismi di Reference-Attention e Audio-Attention, denoisa queste informazioni. Questi passaggi garantiscono che l’identità del personaggio rimanga intatta, al tempo stesso riflettendo accuratamente le dinamiche audio attraverso espressioni facciali e movimenti della testa. Per garantire un flusso video continuo, i Moduli Temporali regolano la velocità del movimento.
Vivi la magia:
- Ritratti Canori: Trasforma un’immagine statica di un personaggio in un avatar che canta, con piena profondità emotiva e posizioni variabili della testa. Indipendentemente dalla durata dell’audio, la nostra tecnologia mantiene consistente l’identità del personaggio per tutto il video.
Scopo e Ispirazione: Questo progetto è realizzato per la ricerca accademica e per mostrare gli effetti. È una testimonianza dell’impegno di Alibaba Group nel superare i limiti dell’IA e dell’apprendimento automatico. Il framework si basa sui fondamenti stabiliti dal progetto Nerfies, dimostrando la nostra dedizione all’innovazione.
Immergiti nel mondo dei ritratti animati con EMO, dove la tua voce dà vita alle immagini in modi senza precedenti.
Official Website
demonstrates its power