Presentiamo VidToMe: potrebbe essere il Gen-1 open-source che attendevi! Con un’ampia gamma di opzioni per modifiche video con testo, modelli personalizzati e guida ControlNet, VidToMe offre un’eccezionale consistenza temporale. Basta un semplice esempio di arte a pixel e ne sarai conquistato!
I modelli di diffusione hanno avviato una generazione di immagini di alta qualità, ma le loro applicazioni nella generazione di video hanno incontrato ostacoli a causa delle complessità del movimento temporale. È qui che entra in gioco l’editing video senza shot, applicando modelli di diffusione di immagini pre-addestrati per riformattare i video originali. Tuttavia, problemi come il mantenimento della coerenza temporale e l’uso efficiente della memoria rimangono.
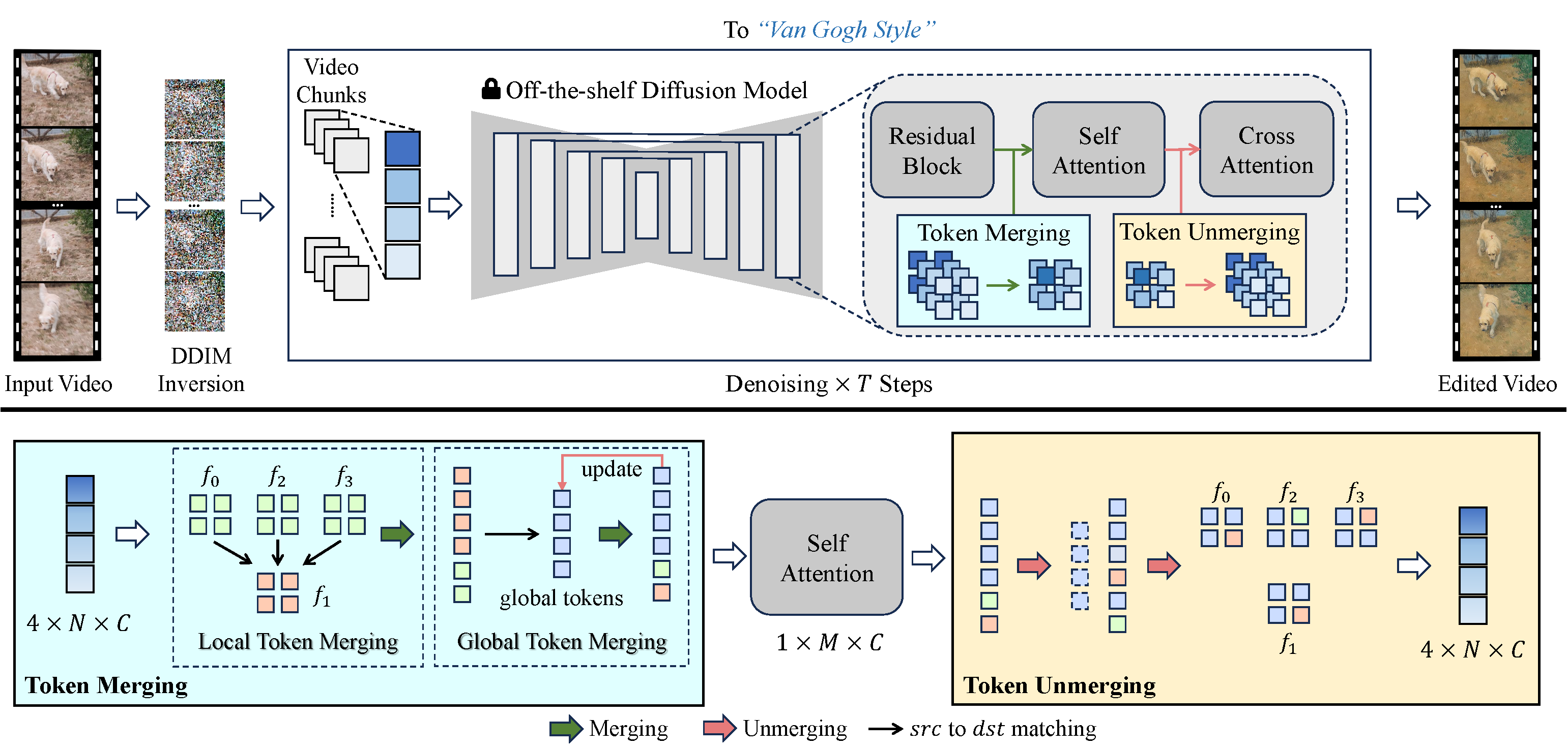
Abbiamo adottato un approccio innovativo per risolvere questi problemi. Miglioriamo la coerenza temporale nei video generati intrecciando token di auto-attenzione tra i frame. Allineando e comprimendo i token temporalmente ridondanti, aumentiamo la coerenza temporale e riduciamo l’uso della memoria. Il nostro processo di fusione unico allinea i token in base alla relazione temporale tra i frame video, garantendo un contenuto video naturalmente coerente.
VidToMe si occupa della pesante elaborazione video. Dividiamo il video in frammenti e applichiamo una fusione locale dei token intra-chunk e una fusione globale dei token inter-chunk. Questo approccio garantisce continuità e coerenza a breve e lungo termine del contenuto video. Superando il divario tra editing di immagini e di video, la nostra tecnica di editing video supera gli attuali standard dell’industria nel mantenimento della coerenza temporale.
Build web-apps using plain english
VidToMe: Video Token Merging for Zero-Shot Video Editing