アリババグループによる革新的なフレームワーク、EMOを紹介します。EMOは、単一の参照画像と会話や歌などの音声クリップを提供するだけで、表情を持つアバタービデオを作成するための魔法を使います。これらのビデオは、表情の動きだけでなく、様々な頭のポーズも特徴とし、提供された音声の時間に合わせることができます。
EMOの仕組み: EMOは2つの主要なステージで機能します:
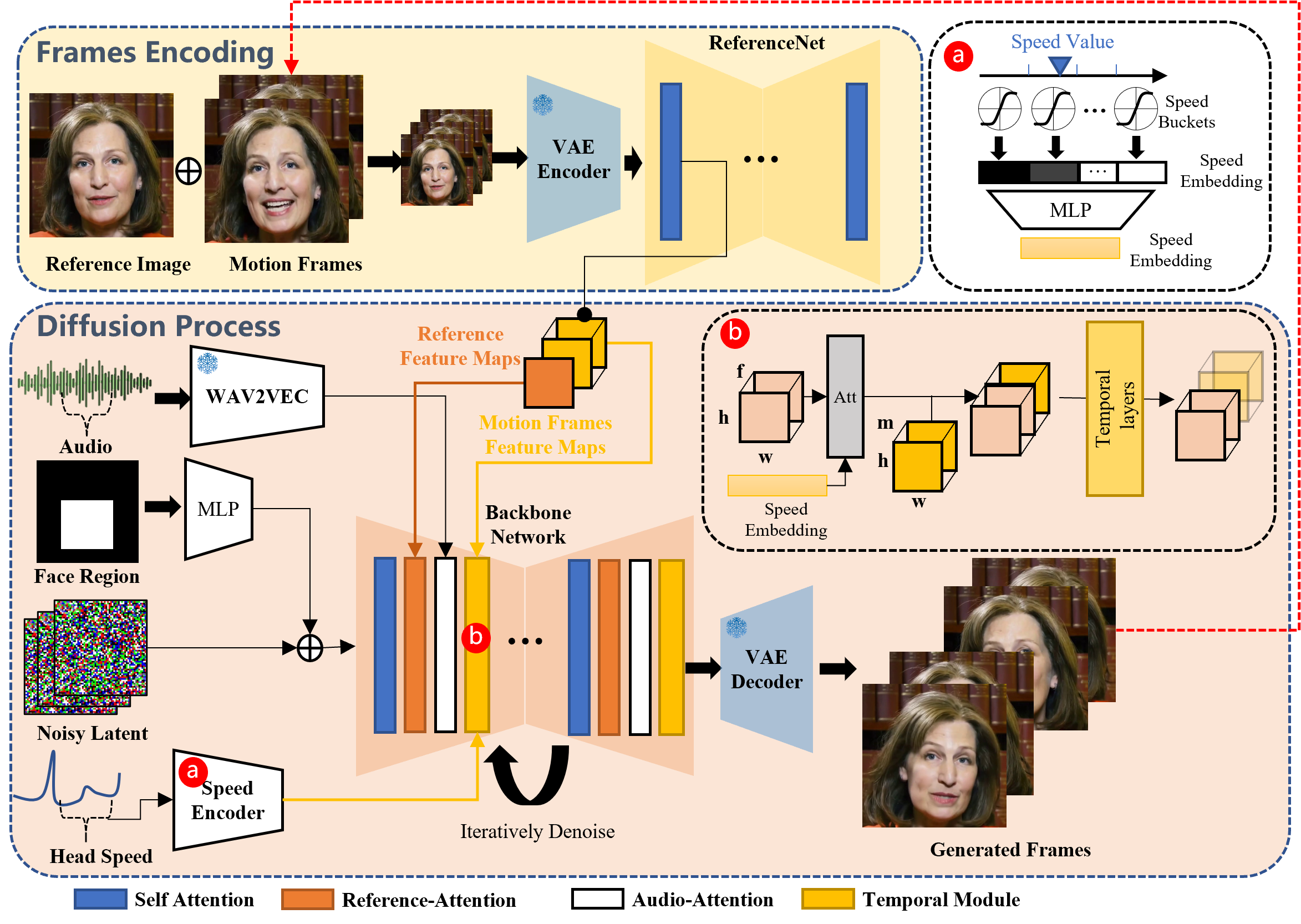
- フレームのエンコーディング: 参照画像とモーションフレームを分析するためにReferenceNetを使用し、重要な特徴をキャプチャします。
- 拡散プロセス: 事前学習済みのオーディオエンコーダーを使用してオーディオ埋め込みを行い、顔の領域マスクとマルチフレームノイズとブレンドします。Reference-AttentionとAudio-Attentionメカニズムを備えたバックボーンネットワークは、この情報をノイズ除去します。これらの手順によって、キャラクターのアイデンティティは保持されたまま、表情と頭の動きを通じて音声のダイナミクスが正確に反映されます。連続した動画の流れを確保するために、Temporal Modulesがモーションの速度を調整します。
魔法を体験してみよう:
- 歌うポートレート: 静止したキャラクター画像を、感情豊かで様々な頭のポーズを持つ歌うアバターに変換します。音声の長さに関係なく、当社の技術はビデオ全体でキャラクターのアイデンティティを一貫させます。
目的とインスピレーション: このプロジェクトは学術研究と効果の紹介のために作成されました。アリババグループのAIと機械学習の領域の限界を押し広げるというコミットメントの証です。このフレームワークは、Nerfiesプロジェクトで確立された基盤の上に構築されており、当社のイノベーションへの取り組みを示しています。
EMOを使って、声が静止画像を前例のない方法で生き生きとしたものにする、アニメーションポートレートの世界に飛び込んでみてください。
Official Website
demonstrates its power