안녕하세요! EMO입니다. 아리바바 그룹이 개발한 혁신적인 프레임워크로, 음성의 힘으로 정적인 초상화를 생동감 있게 만들어줍니다. 하나의 참조 이미지와 말하기 또는 노래하는 음성 클립을 제공하기만 하면, EMO가 마법을 부려 음성 아바타 비디오를 만들어냅니다. 이 비디오는 얼굴 움직임뿐 아니라 다양한 머리 자세도 표현하며, 제공된 음성의 지속 시간에 맞출 수 있습니다.
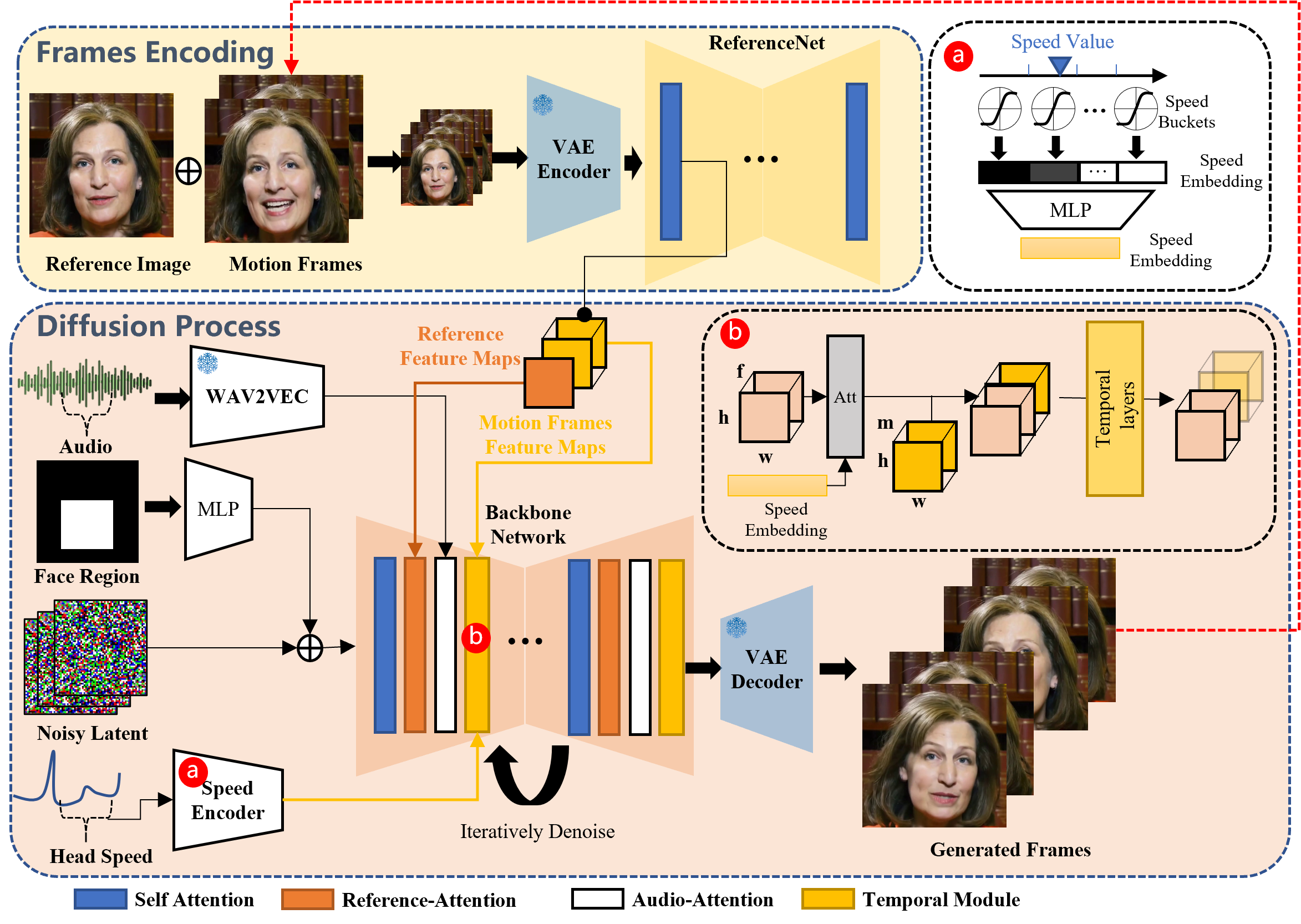
EMO 작동 방식: EMO는 두 가지 주요 단계로 작동합니다:
- 프레임 인코딩: 참조 이미지와 모션 프레임을 분석하기 위해 ReferenceNet을 사용하여 필수적인 특징을 추출합니다.
- 확산 과정: 사전 훈련된 오디오 인코더를 이용하여 오디오 임베딩을 통합하고, 이를 얼굴 영역 마스크와 다중 프레임 노이즈와 결합합니다. 참조-어텐션과 오디오-어텐션 메커니즘을 갖춘 Backbone Network는 이 정보를 노이즈 제거합니다. 이 단계들은 캐릭터의 정체성을 유지하면서도 얼굴 표현과 머리 움직임을 통해 오디오의 역동성을 정확하게 반영합니다. 움직임 속도를 조절하기 위해 시간 모듈이 이용되어 비디오가 자연스럽게 흐를 수 있습니다.
마법 같은 경험:
- 노래하는 초상화: 정적인 캐릭터 이미지를 노래하는 아바타로 변환하여 다양한 머리 자세와 풍부한 감정을 가진 비디오를 만들 수 있습니다. 오디오 길이에 상관없이, 저희 기술은 비디오 전반에 걸쳐 캐릭터의 정체성을 일관되게 유지할 수 있습니다.
목적과 영감: 이 프로젝트는 학술 연구 및 효과 설명을 위해 개발되었습니다. 이는 아리바바 그룹이 인공지능과 기계 학습의 한계를 넓히기 위한 동력을 보여줍니다. Nerfies 프로젝트에서 제시한 기반을 바탕으로 구축된 이 프레임워크는 혁신에 대한 저희의 헌신을 보여주고 있습니다.
EMO와 함께 애니메이션 초상화의 세계로 빠져들어보세요. 여러분의 목소리로 이미지에 생명을 불어넣는 전례 없는 방식으로 경험해보세요.
Official Website
demonstrates its power