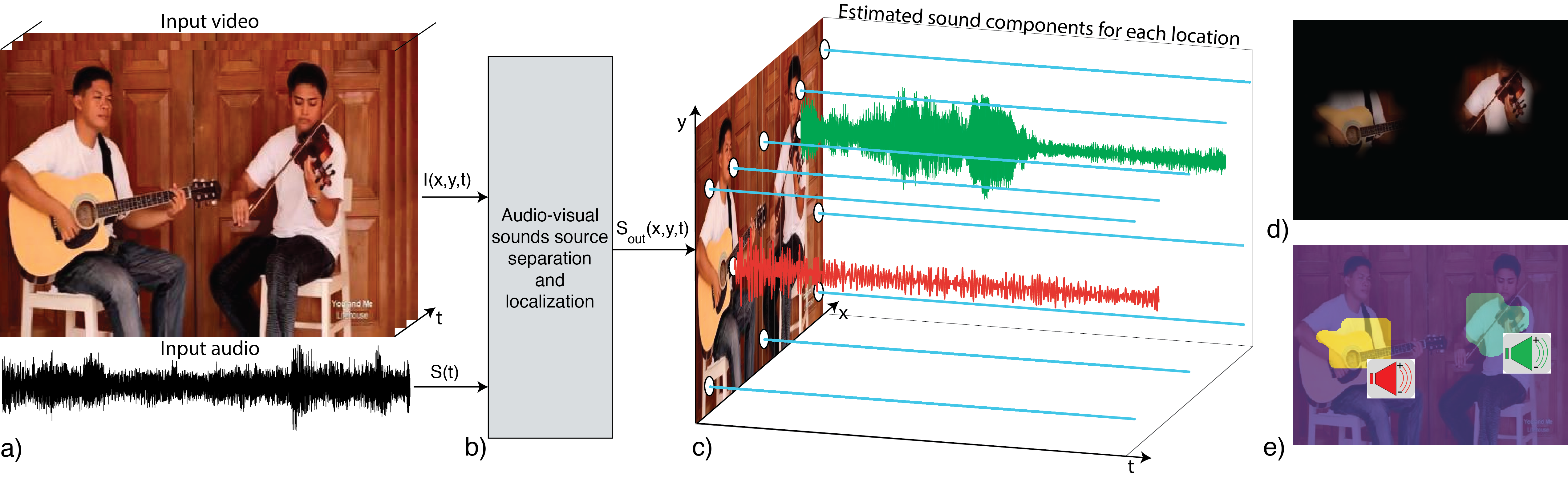
MIT 연구원들이 개발한 혁신적인 도구인 PixelPlayer를 소개합니다. 이 도구는 동영상에서 소리와 상호작용하는 방식을 바꾸어 줍니다. 이 최첨단 시스템은 수동 데이터 라벨링 없이 소리 소스를 구분하고 분리합니다. 말하는 사람을 지정하거나 특정 음표를 식별하는 상상도 해 보세요. 이 모든 것이 자동으로 이루어집니다!
PixelPlayer의 주요 기능:
- 음원 분리: 오디오를 독립된 트랙으로 분할하여 보컬과 악기를 분리합니다.
- 소리 위치 추적: 이 도구는 비디오 프레임 내에서 소리의 원천을 정확히 찾아냅니다.
- 다중 소스 처리: 동시에 발생하는 소리를 인식하고 분리합니다.
작동 원리:
- 비디오 트레이닝: 다양한 악기가 포함된 라벨이 없는 비디오로 시스템을 트레이닝합니다.
- 데이터 기반 학습: PixelPlayer는 이러한 라벨이 없는 비디오로 인공지능을 학습하며, 소리와 이미지 사이의 관계를 스스로 습득합니다.
- 동기화 활용: 시각적 행동과 관련된 소리의 자연스러운 동기화를 잡아냅니다.
- 소리-픽셀 연결: 각 픽셀은 소리 요소가 있어서, 소리의 위치와 분리를 정밀화시킵니다.
- 소리 분리 기술: 고급 알고리즘을 사용하여 각 소리 소스를 개별 채널로 분리합니다.
응용 분야:
- 음악 제작: 편집과 믹싱을 위해 악기를 분리합니다.
- AR/VR에서 소리 위치 추적: 상호작용에 기반한 현실적인 오디오 시뮬레이션으로 사용자 경험을 향상시킵니다.
- AI 더빙: 애니메이션과 비디오 게임의 더빙 작업을 용이하게 해 줍니다.
- 접근성을 위한 자막: 청각 장애인을 위한 정확한 자막과 오디오 설명을 생성합니다.
- 오디오 시각화: 음악과 시각적인 요소를 결합하여 동적인 음악 경험을 제공합니다.
- 음악 교육: 학습자들이 앙상블의 음향 환경을 파악할 수 있도록 도움을 줍니다.
- AI 연구: 다중 모달 인공지능을 발전시켜 인공지능 능력을 향상시킵니다.
PixelPlayer는 오디오-비전 경험을 혁신할 뿐만 아니라 다중 모달 AI 연구를 더욱 발전시킵니다. 다음 링크에서 이 기술에 대해 자세히 알아보세요:
Editing Music in Videos Using AI