Introducing EMO, an innovative framework by Alibaba Group, designed to bring static portraits to life with the power of audio. Simply provide a single reference image and an audio clip, such as talking or singing, and EMO works its magic to create vocal avatar videos. These videos are not only expressive in facial movements but also feature varied head poses, capable of matching the duration of your supplied audio.
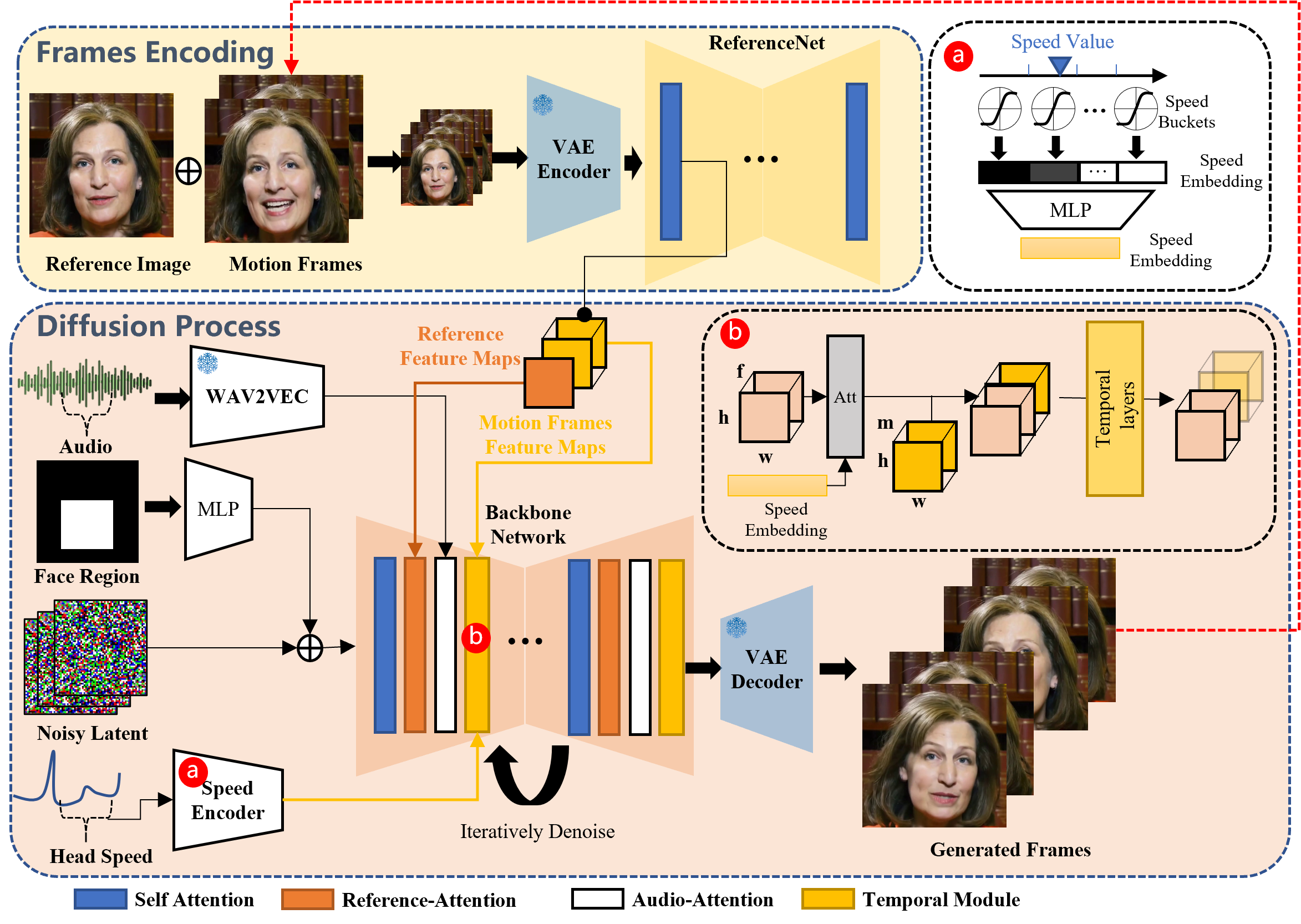
How EMO Works: EMO operates in two main stages:
- Frames Encoding: Utilizes ReferenceNet to analyze the reference image and motion frames, capturing essential features.
- Diffusion Process: Incorporates a pre-trained audio encoder for audio embeddings, blending it with a facial region mask and multi-frame noise. The Backbone Network, equipped with Reference-Attention and Audio-Attention mechanisms, then denoises this information. These steps ensure the character’s identity remains intact while accurately reflecting the audio’s dynamics through facial expressions and head movements. To ensure seamless video flow, Temporal Modules adjust motion velocity.
Experience the Magic:
- Singing Portraits: Transform a static character image into a singing avatar with full emotional depth and varying head poses. Regardless of the audio length, our technology keeps the character’s identity consistent throughout the video.
Purpose and Inspiration: This project is crafted for academic research and showing off the effects. It’s a testament to Alibaba Group’s commitment to pushing the boundaries of AI and machine learning. The framework is built on the foundations set by the Nerfies project, showcasing our dedication to innovation.
Dive into the world of animated portraits with EMO, where your voice brings images to life in unprecedented ways.
Official Website
demonstrates its power