Introducing VidToMe - it may be the open-source Gen-1 you’ve been waiting for! Packed with options for text prompt video edits, custom models, and ControlNet guidance, VidToMe offers exceptional temporal consistency. Just one pixel art example and you’ll be hooked!
Diffusion models have pioneered high-quality image generation, yet their video generation applications have hit stumbling blocks due to temporal motion complexities. That’s where zero-shot video editing steps in, applying pre-trained image diffusion models to reformat original videos. However, issues like maintaining temporal consistency and efficient memory use remain.
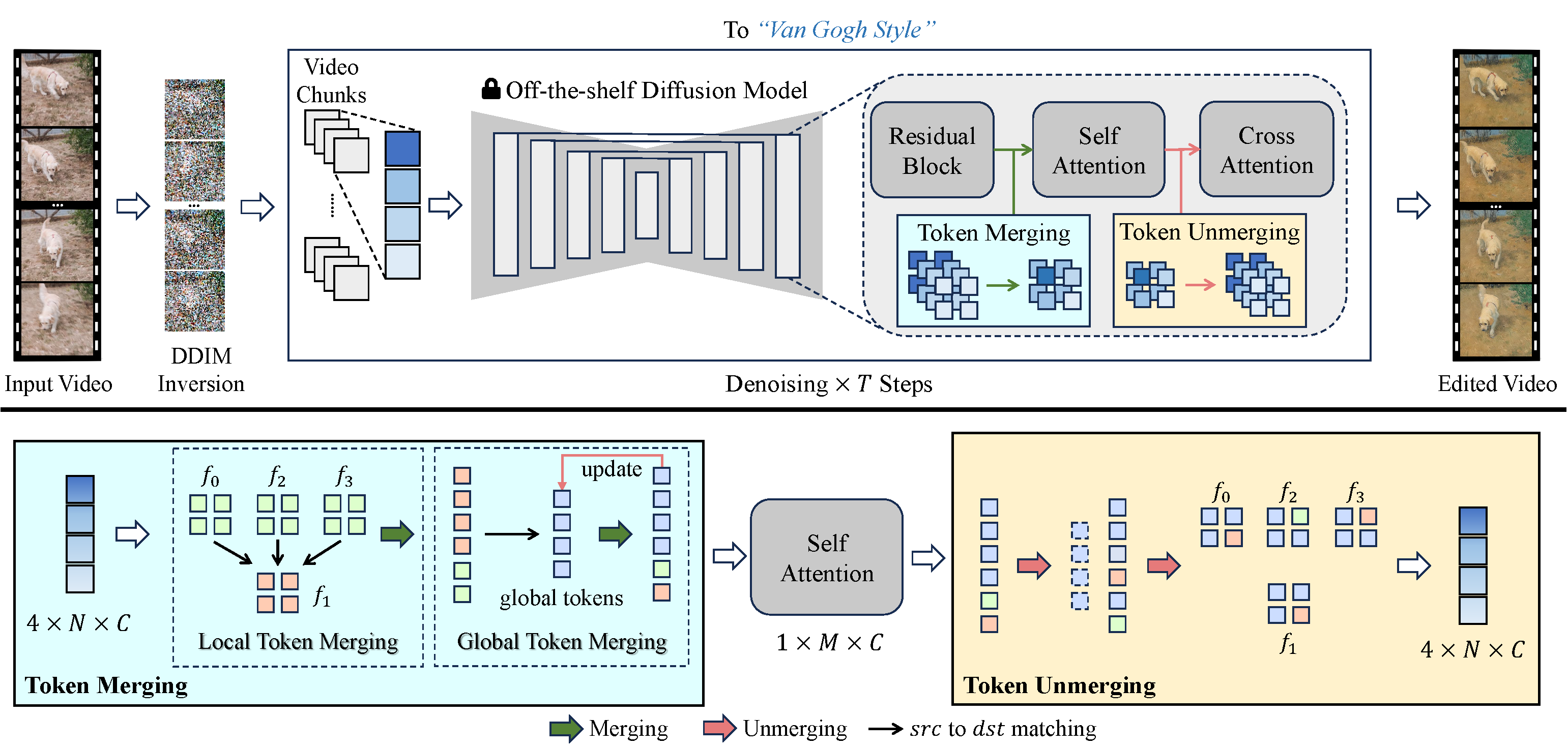
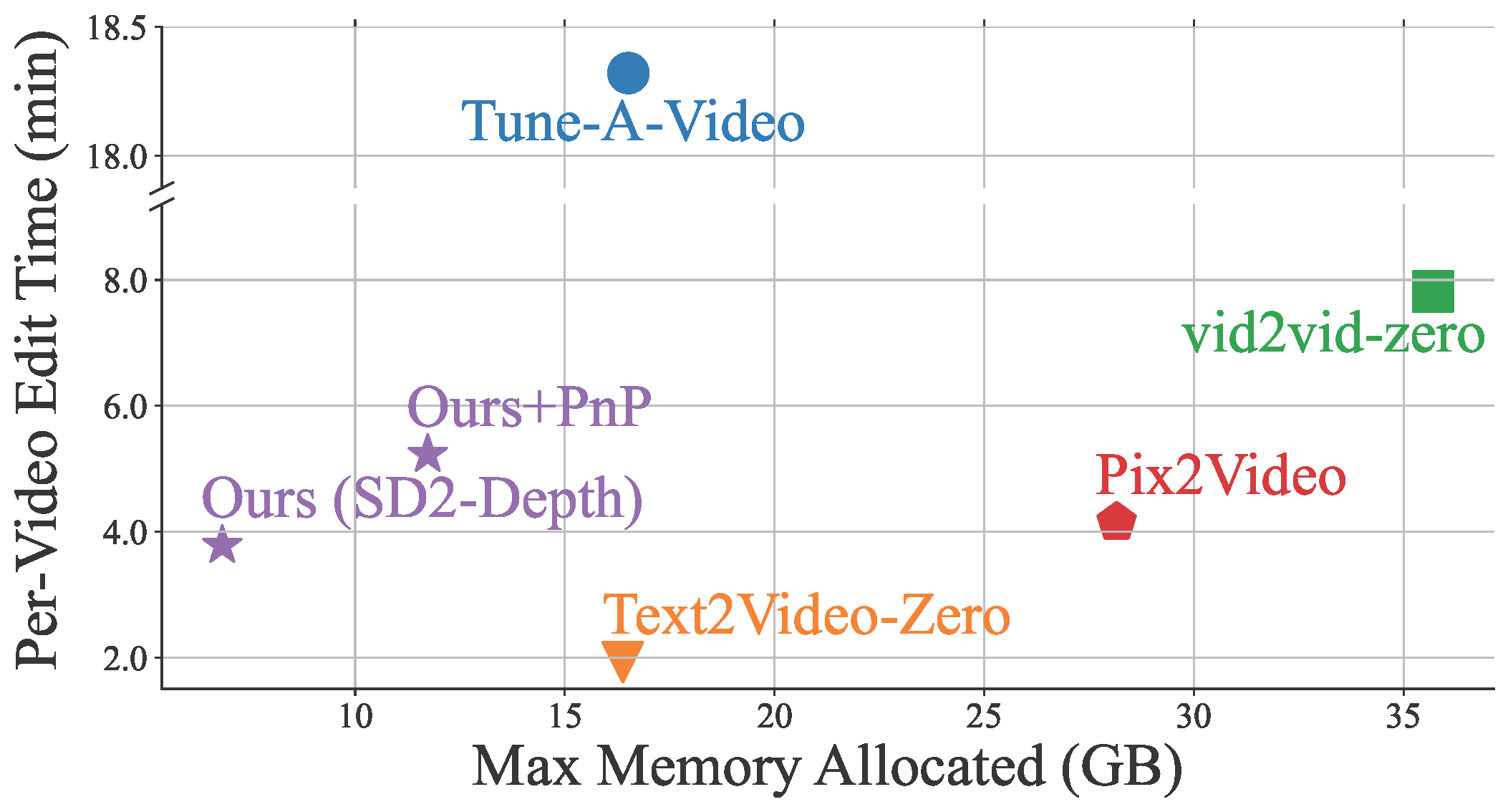
We’ve taken a fresh angle to solve these problems. We enhance temporal consistency in generated videos by interweaving self-attention tokens across frames. By aligning and compressing temporally redundant tokens, we boost temporal coherence and cut down memory use. Our unique merging process lines up tokens based on the temporal relation between video frames, ensuring naturally consistent video content.
VidToMe handles the heavy lifting of video processing. We split the video into chunks and apply intra-chunk local token merging and inter-chunk global token merging. This approach guarantees short and long-term continuity and consistency of video content. Bridging the gap between image and video editing, our video editing technique surpasses current industry standards in maintaining temporal consistency.
Build web-apps using plain english
VidToMe: Video Token Merging for Zero-Shot Video Editing