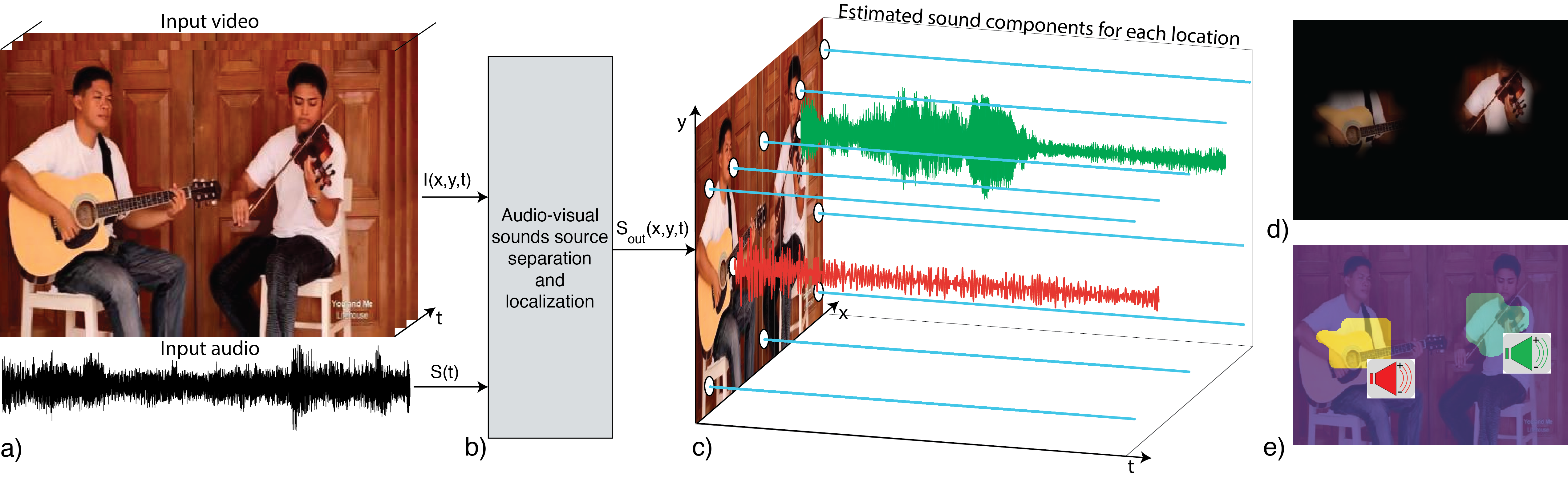
发现PixelPlayer,这是由麻省理工学院的研究人员开发的一种创新工具,它改变了我们与视频中的声音互动的方式。这一前沿系统能够在没有手动标注数据的情况下,区分和分离声音源。想象一下,自动定位正在讲话的人或识别特定的乐音!
PixelPlayer在以下方面表现出色:
- 声音源分离: 它将音频分割成不同的轨道,隔离人声和乐器。
- 声音定位: 该工具可准确定位视频画面中的声音来源。
- 多源处理: 可识别和分离同时发生的声音。
工作原理:
- 视频训练: 使用带有各种乐器的未标注视频进行系统训练。
- 数据驱动学习: PixelPlayer从这些未标注的视频中自我学习,掌握声音与图像的关系。
- 同步利用: 它捕捉到视觉动作和相关声音之间的自然同步。
- 声音-像素关联: 每个像素都有一个声音组件,优化声音的定位和分离。
- 声音分离技术: 先进的算法将音频解缠,为每个声音源生成独立的声道。
应用场景:
- 音乐制作: 隔离乐器以进行编辑和混音。
- 增强现实/虚拟现实中的声音定位: 通过模拟真实的基于互动的音频,提升用户体验。
- 人工智能配音: 简化动画和视频游戏中的配音任务。
- 无障碍字幕: 为听力障碍者创建准确的字幕和音频描述。
- 音频可视化: 将声音与视觉图像相连,创造动态音乐体验。
- 音乐教育: 帮助学习者把握合奏的音响风景。
- 人工智能研究: 推动多模态人工智能的发展,丰富人工智能的能力。
PixelPlayer不仅革新了音视频体验,还促进了多模态人工智能研究的进一步发展。了解一下这项引起轰动的技术:
Editing Music in Videos Using AI