介绍VidToMe - 这可能是您一直在等待的开源Gen-1! VidToMe拥有丰富的选项,可用于文本提示视频编辑、自定义模型和ControlNet引导,提供出色的时间一致性。只需一个像素艺术示例,就能让您着迷!
扩散模型开创了高质量图像生成的先河,但由于时间运动复杂性,其视频生成应用遇到了阻碍。这就是零样本视频编辑介入的地方,将预训练的图像扩散模型应用于重新格式化原始视频。然而,仍然存在保持时间一致性和高效内存使用的问题。
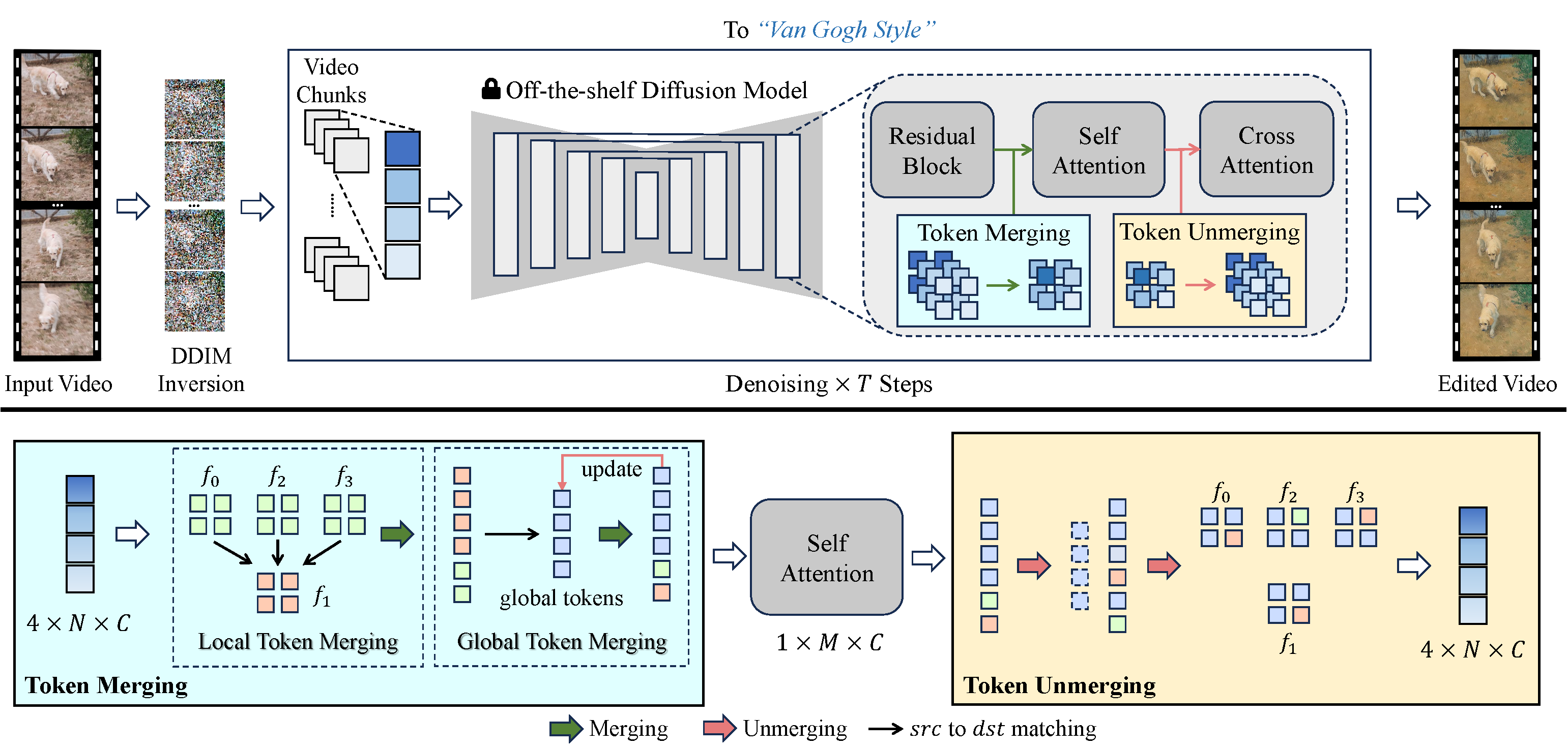
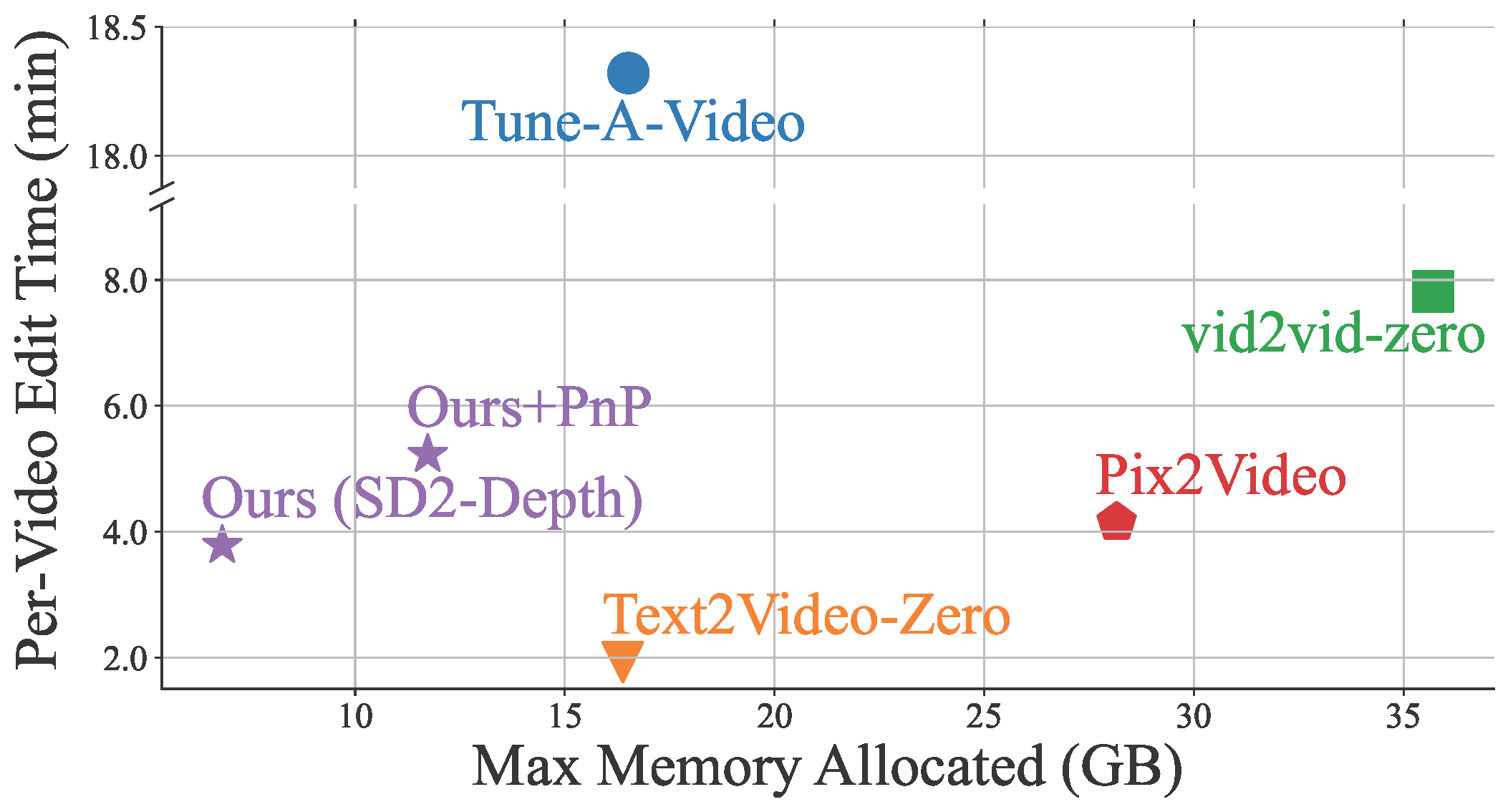
我们采取了一个新的方式来解决这些问题。我们通过在帧之间交织自注意力标记来增强生成视频的时间一致性。通过对时间上冗余的标记进行对齐和压缩,我们提高了时间上的连贯性,并减少了内存使用。我们独特的合并过程根据视频帧之间的时间关系对齐标记,确保自然一致的视频内容。
VidToMe处理视频处理的繁重工作。我们将视频分成块,并应用块内局部标记合并和块间全局标记合并。这种方法保证了视频内容的短期和长期的连续性和一致性。作为图像和视频编辑之间的桥梁,我们的视频编辑技术在保持时间一致性方面超越了当前行业标准。
Build web-apps using plain english
VidToMe: Video Token Merging for Zero-Shot Video Editing